音频文件格式相关。
音频简介
一个mp3是320kbps,44100hz的,这是什么意思?
44100Hz代表的是信号的采样率。所谓采样,就是每隔单位时间获取一次当前时刻声波的y值。采样是将连续的数据离散化的过程(将模拟信号转为数字信号)。 图片来源
图片来源
以上提到的采样方法叫做PCM(脉冲编码调制,Pulse Code Modulation)。根据Nyquist-Shannon采样定律,采样率至少应该是你的目标最高频率的两倍。人耳的听觉范围大概是20Hz-20000Hz (如果你好奇自己能听见多高的声音的话,可以点击这里测试你的耳朵) ,虽然录音软件常常也有48000hz的选项,但是我们可以安全地得出结论:44100Hz几乎可以满足我们所有的需求,更高的只不过在浪费你的内存和cpu。超过48000的采样对人耳已经没有意义,这和电影的每秒 24 帧图片的道理差不多。44100Hz恰好是几乎所有发行音乐的标准采样率。事实上,对于人声以及很多乐器来说,高频的声音是噪音,因而,高采样率有时会让你的音质变差(所以我们需要调整EQ)。
320kbps代表着它的码率/比特率(bite rate),它是kilobits per second的缩写,代表着用来描述声音的数据大小。在CD(未经压缩的音频文件)里,码率为1411.2kbps,而达到CD音质的mp3音质应当高于128kbps / 44100Hz(128kbps可以说是最常见的比特率了)。 通常来说一个更大的数字代表着更好的品质。品质取决于很多因素(比如编码的算法)。很多时候我们不需太高的比特率:我们的设备播放出的mp3和CD可能并无区别(声卡/音响普通)。
一个wav是44100Hz 16bit stereo 或者 22050Hz 8bit mono,这又是什么意思?stereo/mono指的是双/单声道。对于单声道声音文件,采样数据为八位的短整数(short int 00H-FFH);而对于双声道立体声声音文件,每次采样数据为一个16位的整数(int),高八位(左声道)和低八位(右声道)分别代表两个声道。
声音是一种机械波,由物体振动产生,需要介质来传播。所以,从本质上讲,声音就是一段时间轴上的波形。
声音有三要素:音调、响度和音色:
- 音调由声波的频率决定,频率越高音调越高。
- 响度由声波的振幅决定,振幅越高响度越大。
- 音色是由波形的“形”决定的(像方波,三角波,锯齿波这样的声音被称为脉冲波,它们声音单一)。
一个音频文件,是将模拟信号转换为数字信号得到的文件。一般有5个重要参数:编码方式、声道数、采样率、位深、码率。
- 编码方式:这个格式是怎么组织二进制数据的以及压缩方式等。
- 声道数:单声道、双声道还是5.1声道等。
- 采样率:每秒采样的次数。
- 位深:用来存储采样点y值所使用的二进制位个数。
- 比特率:该文件每秒的所需的二进制位个数。
我们知道WAV格式是不存在压缩的,因此,它的编码方式就是直接把所有采样的点按顺序排列写到文件里。
WAV文件大小 (B) = 声道数 * 采样率 (Hz) * 位深 (bit) / 8 + 文件头的大小 (B,是44B)
具体实现
当你使用文本编辑器打开mp3或是wav文件,你看到的是这样的数字:
1
2
3
4
5
6
7
8
9
104944 3303 0000 0000 3d48 5459 4552 0000
0006 0000 0032 3031 3800 5444 4154 0000
0006 0000 0032 3230 3300 5449 4d45 0000
0006 0000 0031 3430 3600 5052 4956 0000
168e 0000 584d 5000 3c3f 7870 6163 6b65
7420 6265 6769 6e3d 22ef bbbf 2220 6964
3d22 5735 4d30 4d70 4365 6869 487a 7265
537a 4e54 637a 6b63 3964 223f 3e0a 3c78
3a78 6d70 6d65 7461 2078 6d6c 6e73 3a78
3d22 6164 6f62 653a 6e73 3a6d 6574 612f
1 | 5249 4646 2e3d 0e05 5741 5645 666d 7420 |
这上面是同一首歌的mp3/wav格式。它们的区别在哪里?
WAV
结构
文件头
WAV格式遵循RIFF资源交换档案格式,所以WAV格式其实是一个三层关系,这里简化了一下,它的文件头格式如下表:
| 地址 | 大小 | 类型 | 内容 |
|---|---|---|---|
| 00H-03H | 4 | char*4 | 资源文件交换标志RIFF |
| 04H-07H | 4 | unsigned int | 从下个地址开始到文件末尾的字节数 |
| 08H-0BH | 4 | char*4 | WAV文件标志WAVE |
| 0CH-0FH | 4 | char*4 | 波形文件标志fmt ,最后一位是0x20空格 |
| 10H-13H | 4 | unsigned int | 子Chunk的文件头大小,对于WAV这个子Chunk该值为0x10 |
| 14H-15H | 2 | unsigned short | 格式类型,值为1时,表示数据为线性PCM编码 |
| 16H-17H | 2 | unsigned short | 声道数 |
| 18H-1BH | 4 | unsigned int | 采样频率 |
| 1CH-1FH | 4 | unsigned int | 波形文件每秒的字节数=采样率PCM位深/8声道数 |
| 20H-21H | 2 | unsigned short | DATA数据块单位长度=声道数*PCM位深/8 |
| 22H-23H | 2 | unsigned short | PCM位深 |
| 24H-27H | 4 | char*4 | 数据标志data |
| 28H-2BH | 4 | unsigned int | 数据部分总长度(字节数) |
1 | struct WAVHeader |
数据组织方式
在文件头之后,就是WAV文件的数据部分了。它的数据组织方式是:第一个采样点的左声道值,第一个采样点的右声道值,……,最后一个采样点的左声道值,最后一个采样点的右声道值。每一个值都有位深个比特。
生成一段简易wav
首先将Wav Header填写好。
1 | WAVHeader getHeader(int num) |
首先,定义键名——频率对照表。
1 | const double keyf[]= |
这里是声音频率与键名的对照表,你可以看到大名鼎鼎的A4(440hz)。我一年前的FPGA实验写的是键盘电子琴,其实这两个做的都是一样的事。我想起当时我试图用一个蜂鸣器发出多个声音,并没有成功(最后还是给左手/右手各分配了一个蜂鸣器),在看了这个How Oldschool Sound/Music worked之后我意识到这也许是可以做到的,(但是也许)需要傅里叶。
说到傅里叶,我在看关于mp3压缩的算法时看到了FFT,意识到我遇到过的噪音消除都用的是FFT算法(Cool Edit提取的噪声文件似乎就是.fft?我感觉这个值得一篇单独的博文)。
定义一些常量:
1 | const int F=48000; ///音乐采样率,单位Hz |
下面是生成方波、三角波、噪声波的函数:
1 | ///给定时间t,不同波形的值 |
使用二进制方式读写文件,使用fwrite进行二进制输出。
1 | FILE *fp=fopen("test.wav","wb"); |
MP3
尽管有许多创造和推广其他格式的重要努力,如 MPEG 标准中的 AAC(Advanced Audio Coding)和 Xiph.Org 开源无专利的 Vorbis. MP3 (MPEG-1 Audio Layer3),这种来自德国的音频格式,仍然是最被人熟知的。
一个MP3文件分为3部分:TAG_V2(ID3V2),Frame, TAG_V1(ID3V1).
| MP3 | 内容 |
|---|---|
| ID3V2 | 包含作曲,专辑等信息,长度不固定,ID3V1的扩展 |
| Frame | 一系列的帧,个数和帧长不固定 |
| ID3V1 | 包含作者,作曲,专辑等信息,长度为128byte |
结构
ID3V2
ID3V2存放在MP3文件的首部,由1个标签头和若干标签帧组成。
标签头为10个字节,
1 | char Header[3]; /*必须为"ID3"否则认为标签不存在*/ |
每个标签帧都有一个10个字节的帧头和至少一个字节的不固定长度的内容组成为,帧头的定义如下:
1 | char FrameID[4]; /*用四个字符标识一个帧,说明其内容,稍后有常用的标识对照表*/ |
Frame
帧的个数由文件大小和帧长决定,每个帧的长度可能固定,由码率决定。一个帧分为帧头和数据实体两部分,帧头记录了mp3的码率,采样率,版本等信息,帧之间相互独立。
| Frame格式 | 大小 |
|---|---|
| FRAMEHEADER | 4 byte |
| CRC(free) | 0/2 byte |
| MAIN_DATA | 由frame header计算得出 |
ID3V1格式
ID3V1存放在MP3文件结尾,共128bytes,各项信息都顺序存放,不足部分使用‘\0’补足。
1 | typedef struct tagID3V1 |
编码
MP3的首尾都是标记身份的信息,中间的frame则是音频的编码。MP3运用心理学声(Psychoacoustic, 将人类听觉范围外的声音舍弃;simultaneous masking: 如果同时有强声&弱声,舍弃弱声)等技术,舍弃了脉冲编码调制 (PCM) 的音频中对人类听觉不重要的数据。它的前身MP2,来源于为EUREKA (就是阿基里德从浴盆里跳出来的时候大喊的那个eureka) 项目资助的数字音频广播项目DAB. MP2的压缩率大概在6:1 ~ 8:1,但当时的计算机硬盘普遍只有500MB,这样的音频还是略显奢侈了。而MP3可以将一个完整的音乐文件压缩到原件的8%,权衡了数据大小和音质质量。
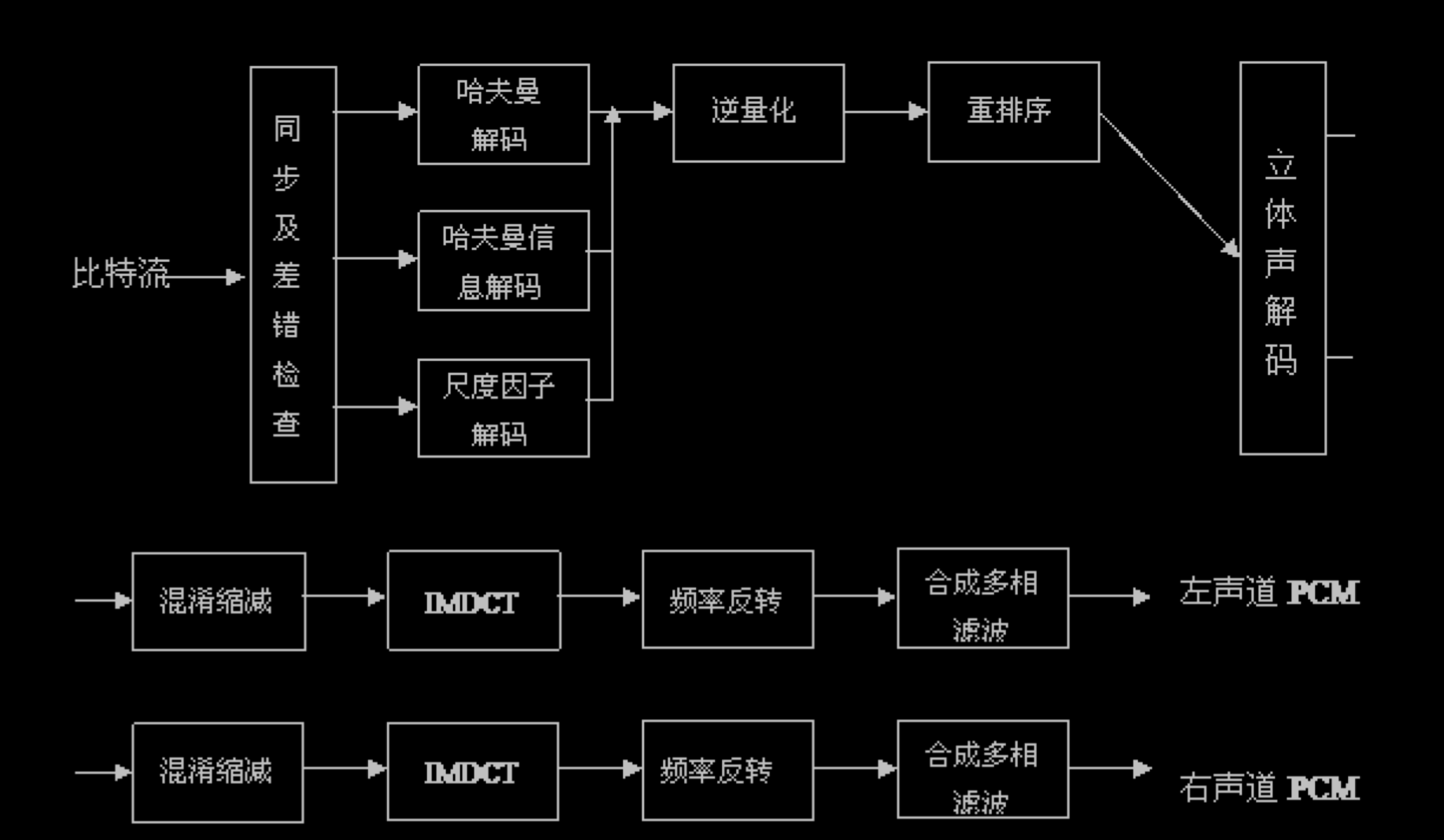
关于编码的详情在资料的[5], [6].
一点无关的东西:由于CD介质的Tom’s Diner (Suzanne Vega)柔和,旋律简单,因此容易听到压缩格式的缺陷,发明者布兰登堡便使用这首歌来评价MP3算法的优劣。因而,有人开玩笑地称Suzanne Vega为“MP3之母”。出于好奇,我查了一下这首歌,和Fall Out Boys的Centuries开头简直一模一样,可能是某种致敬。
资料来源
[1]mp3编码分析
[2]mp3维基
[3]wav格式详解
[4]声音的产生与数字化
[5]MP3压缩算法
[6]MP3解码算法原理解析