从流水线 (pipeline) 到乱序执行 (out-of-order),处理器的指令级并行保证了其性能上的绝大提升。但是在性能提升的同时,安全性的问题也随之出现。这篇博客主要介绍预测执行攻击。
本文是在USTCLUG weekly party上的讲稿,直接使用了很多博客里的图片,引用源都列在了参考章节。
词汇解释
乱序 (out-of-order)
循序执行 (in-order)
在早期的处理器中,指令的执行一般在以下的步骤中完成:
- 指令获取。
- 如果输入的运算对象是可以获取的(比如已经存在于寄存器中),这条指令会被发送到合适的功能单元。如果一个或者更多的运算对象在当前的时钟周期中是不可获取的(通常需要从主存获取),处理器会开始等待直到它们是可以获取的。
- 指令在合适的功能单元中被执行。
- 功能单元将运算结果写回寄存器。
乱序执行 (o3)
这种范式通过以下步骤挑选可执行的指令先运行:
- 指令获取。
- 指令被发送到一个指令序列中(也称执行缓冲区或者保留站(reservation station))。
- 指令将在序列中等待直到它的数据运算对象是可以获取的。然后指令被允许在先进入的、旧的指令之前离开序列缓冲区。
- 指令被分配给一个合适的功能单元并由之执行。
- 结果被放到一个序列中。
- 仅当所有在该指令之前的指令都将他们的结果写入寄存器后,这条指令的结果才会被写入寄存器中。这个过程被称为毕业或者退休(retire)周期。
乱序执行的重要概念是实现了避免计算机在用于运算的对象不可获取时的大量等待。在上述文字的要点中,乱序执行处理器避免了在顺序执行处理器处理过程第二步中当指令由于运算数据未到位所造成的等待。

Tomasulo算法
在处理器中,先后执行的指令之间经常具有相关性(例如后一条指令用到前一条指令向寄存器写入的结果),因此早期简单的处理器使后续指令停顿,直到其所需的资源已经由前序指令准备就绪。Tomasulo算法则通过动态调度的方式,在不影响结果正确性的前提下,重新排列指令实际执行的顺序(乱序执行),提高时间利用效率。

旁路攻击 (side-channel attacks)
较之暴力破解攻击和密码算法的理论性弱点分析,旁路攻击侧重的是物理信息,例如时间,功率消耗,点此邪路或是声音。它的信息来源于计算机系统如何被implement,而不是被implement的算法或是设计。这些是“额外的信息”,所以被称为side-channel.
根据借助的介质,旁路攻击分为多个大类,包括:
- 缓存攻击,通过获取对缓存的访问权而获取缓存内的一些敏感信息,例如攻击者获取云端主机物理主机的访问权而获取存储器的访问权,我们接下来会讲到的大部分预测执行攻击都属于缓存攻击;
- 计时攻击,通过设备运算的用时来推断出所使用的运算操作,或者通过对比运算的时间推定数据位于哪个存储设备,或者利用通信的时间差进行数据窃取,NetSpectre就是计时攻击的一个例子。
除此之外,还有基于功耗监控的旁路攻击,电磁攻击(如TEMPEST攻击),差别错误分析,数据残留等等,但是在这种攻击下在预测执行的前提下很难实现,就不展开讲了。
所有的攻击类型都利用了加密/解密系统在进行加密/解密操作时算法逻辑没有被发现缺陷,但是通过物理效应提供了有用的额外信息(这也是称为“旁路”的缘由),而这些物理信息往往包含了密钥、密码、密文等隐密数据。
虚拟内存 (virtual memory)
在现代计算机中,将虚拟地址转换为物理地址是非常常见的操作。如果把这个工作交给操作系统,那就太慢了。现代CPU硬件提供了一种称为TLB (Translation Lookaside Buffer) 的缓存,该设备可缓存最近使用的映射。这样,CPU大部分时间都可以直接在硬件中直接执行地址转换。

从上图中我们可以看到一个内存地址的翻译过程:首先在TLB中查找,如果在TLB中没有找到对应条目,则在页表中去寻找,如果成功了,则返回地址,并将它加入TLB,如果也失败了,操作系统会raise一个page fault.

上图是现代计算机中虚拟内存的一个示例 (pre-meltdown),红色是内核内存(只有操作系统可以访问),蓝色是用户程序的内存,蓝色是未分配的内存。
每一个页面 (page, 常见的page size是4KB) 都有一个permission bit,标志他是否是内核内存。如果一个用户程序师徒访问内核内存,就会导致page fault,操作系统在此时会终止此次访问。
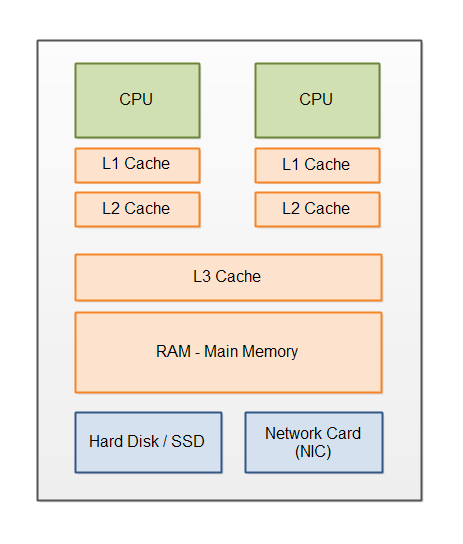
缓存 (cache)
在计算机系统中,CPU高速缓存(英语:CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。
预测执行 (speculation execution attack)
预测执行是优化技术的一类,采用这个技术的计算机系统会根据现有信息,利用空转时间提前执行一些将来可能用得上,也可能用不上的指令。如果指令执行完成后发现用不上,系统会抛弃计算结果,并回退 (squash) 执行期间造成的副作用。 推测执行的目标是在处理器系统资源过剩的情况下并行处理其他任务。推测执行无处不在。流水处理器的分支预测、数值预测、 预读取内存和文件、以及数据库系统的乐观并发控制等机能中都采用到了推测执行。
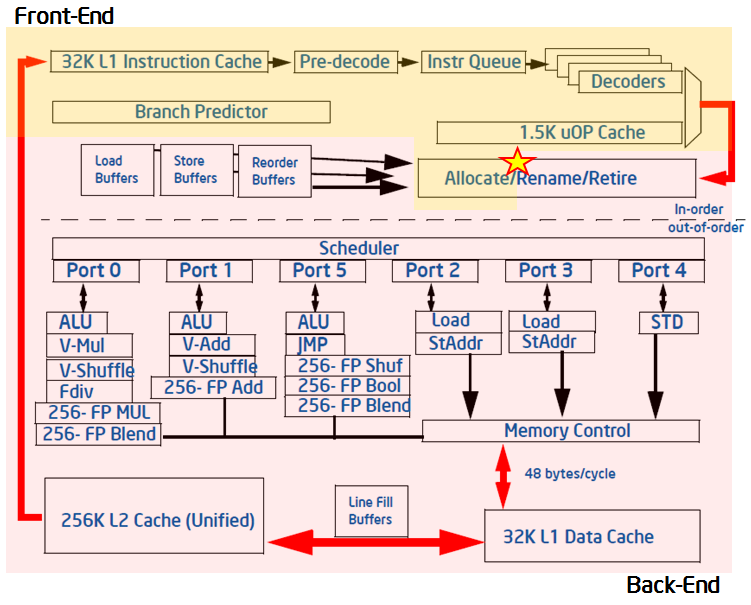
上图是一个现代处理器的执行引擎。我们知道,处理器有多级缓存,每一级的缓存miss都会延迟程序执行的时间,为了优化时间上的性能,现代处理器引入了预测执行,举一个简单的例子:
1 | if(x < array_size){ |
想象这样一个情形:当执行这个代码时,array_size并不在内存中,与其原地空等它的值,不如让分支预测单元 (BPU, Branch Prediction Unit) 预测一下这个if判断是1还是0,然后根据它的预测,在等待array_size的时间内执行BPU选择的代码块的指令。如果后来发现BPU判断错误,也没有关系,处理器只要抛弃此时预测执行的指令所产生的计算结果,回退到if判断指令就行了。此时的时间性能仍然不会比空等更糟。
另一类常见的预测执行被称为间接分支预测 (indirect branch predict),由于动态调度 (virtual dispatch),这个情形非常普遍。
1 | class Base { |
在机器代码中,这一代码段的实现方式是让目标文件 (obj) 从指向的内存位置加载虚拟调度表 (v-table),然后调用它。由于此操作非常普遍,因此现代CPU具有各种内部缓存,并且经常会猜测间接分支将到达的位置并在该点继续执行。同样,如果处理器猜对了,它可以继续节省大量时间。如果不是这样,它可能会丢弃推测性的计算并重新开始。
熔断 (Meltdown): 流水线带来的挑战
一般来说,普通的用户应用不能够随意地访问内核内存。Meltdown将用户内存和内核内存的安全界限模糊 (melt)了,所以被称为meltdown.
伪码
1 | //assume probe array is flushed |
注释
指令一会导致操作系统抛出异常(内核内存页权限位与用户内存不同),在抛出异常之前,由于预测执行,指令二会将本来不应该访问的内核内存地址存入缓存中。
probe_array是提前分配好内存的数组,这就是我们的旁道 (side-channel),攻击者会确保在指令一之前,probe_array所有的项都不在缓存里。
这里的rdtscp()是intel 64和IA-32架构上的一个Read Time-Stamp Counter and Processor ID函数。处理器中有一个时间戳寄存器 (time-stamp register),这个函数会读取它的值,提供处理器时钟周期级别的时间 (GHz instead of ms)。
1 | static inline __attribute__((always_inline)) uint64_t rdtscp(void) |
Meltdown出现不是因为乱序执行 (out-of-order),流水线处理器都有可能有此安全缺陷。指令1和2虽然有数据依赖,但只要在流水线情形下,就可能在page fault之前把内核地址内容取进缓存里。
旁道攻击一般分为三个阶段:access - transit - recover. 在上面的伪代码中,指令1是access phase (接触到秘密地址),指令2是transit phase (将秘密保存到旁道中),后面攻击者做的工作是recovery phase:通过计时等方法把秘密恢复出来。
补丁
你可能会想了,这个问题并不难解决,只要在预测执行的时候也检查权限位就好了。事实也是这样,在预测执行时略过权限检查并不能带来多少性能提升。这也是meltdown (与spectre比较)的补丁更加简单,易于理解的原因。
拿Linux的meltdown补丁来讲,KPTI (Kernel Page Table Isolation, 原KAISER) 是一个软件补丁,它的原理简单来说是这样的:当程序在用户空间中运行时,内核内存时不将其映射到程序中。如果运行时出现映射不存在的情况,则推测执行将被停止,直接fault.

听起来非常直接美好,但是这个软件补丁会造成不小的性能下降。可以想象,如果没有硬件上的支持,由于用户态和内核态的频繁切换,页表也会被频繁更改,TLB也需要被flush.
在/sys/devices/system/cpu/vulnerabilities/下有处理器漏洞的log,在我设备上是这样的:
1 | elisa:~$ ls /sys/devices/system/cpu/vulnerabilities/ |
我们来查看一下meltdown的补丁:
1 | cat /sys/devices/system/cpu/vulnerabilities/meltdown |
幽灵
幽灵 (spectre) 得以存在的根本原因是预测执行 (speculation execution),比起熔断,它跟不容易被攻击者利用,然而,它的防治并没有Meltdown那么简单。
分类
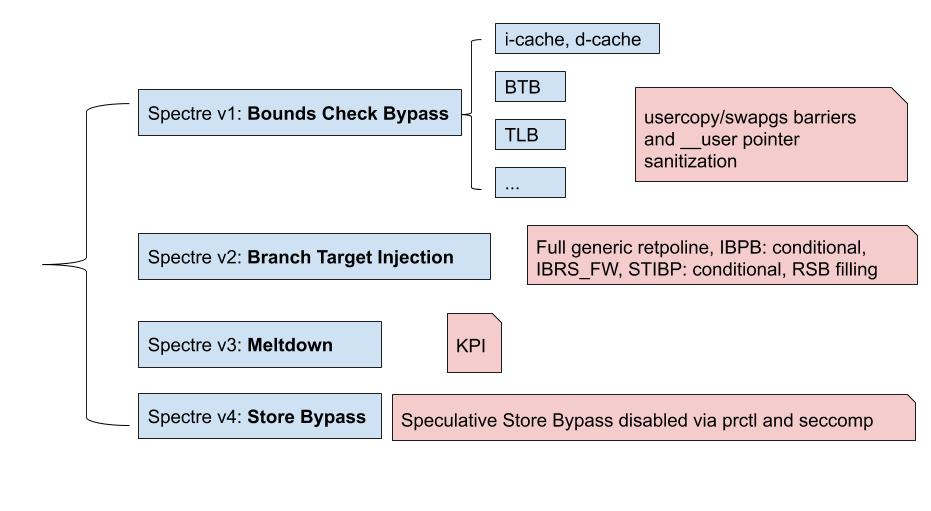
我们把Spectre根据access phase分成四类,其中的Spectre v3就是刚刚讨论过的meltdown,接下来我们将展示Spectre v1的伪代码,并演示v1和v4的几种变种 (variant).
Spectre v1 伪码
1 | // assume probe_array is flushed from cache |
上面展示的是一个基于d-cache的Spctre v1 (Bounds Check Bypass). Spectre的原理与Meltdown类似,他们都是利用wrong-path的预测执行,让秘密进入我们设好的旁道中。在这个伪代码中,旁道是cache,它也可以是BTB,TLB. 所有会在预测执行时被更改状态,并在squash的时候没有恢复的组件,都是潜在的旁道。
近期出现的许多攻击也证明了之前很多研究只着眼缓存并不是明智的选择。例如NetSpectre利用了AVX (Advanced Vector Extensions) 的隐秘信道 (60 bit per hour),它是一个计时攻击。它的原理很简单,AVX有一个优化:在做大数计算时会打开一个优化单元(平时是关闭的),所以攻击者可以通过预测执行来判断想要知道的秘密是否是大数,这个可以简要理解成0和1的区别,能够分辨0和1,就有了可以缓慢读出整个内存的能力。
Foreshadow则是利用了Intel的SGX (Software Guard eXtensions) 模块,SGX的保护方式并不是识别和隔离平台上的所有恶意软件,而是将合法软件的安全操作封装在一个enclave中,保护其不受恶意软件的攻击。而且执行SGX的权限非常高,特权或者非特权的软件都无法访问enclave,也就是说,一旦软件和数据位于enclave中,即便操作系统管理员和VMM(Hypervisor)也无法影响enclave里面的代码和数据。Enclave的安全边界只包含CPU和它自身。Foreshadow证明了这样的enclave制造的界限也能被预测执行攻击打破。
SmotherSpectre则利用了intel处理器hyperthreading时的co-schedule (multi-threading).
在这个仓库里有Spectre v1 cache的PoC.
Spectre v2 解释
Spectre v2 利用的是Indirect Branch Injection. 从上一节我们知道,攻击者可以通过训练分支预测模块来读取内存中的内容。间接分支 (indirect branch) 在现代CPU中非常常见,包括BHB (Branch History Buffer), IBTB (Indirect Branch Target Buffer) 和 RSB (Return Stack Buffer). (之前我们v1训练的是BTB).
Spectre v4 解释
Spectre v4利用的是Store Bypass, 一个简单的伪代码可以是这样的:
1 | str[0]=malicious_x; // load quickly |
通过指令1,将攻击者本来不能得知的数据存入数组str中的某一项,在指令2中缓慢地将这一项的地址计算出来,抹去秘密数据。这样数据在architecture的层面上就没了痕迹,但是在microarchitectural的层面上留下了,这就是旁道攻击的原理。
PoC
我们即将展示几种攻击,包括硬件上的攻击和模拟器上的攻击。
一般Spectre-like的攻击都是通过“训练”预测部件来使用wrong-path攻击,根据最初的spectre paper, 一般这个speculation window的大小平均能有100多条指令
a. 攻击者和受害者通过一个probe array对一些共有资源竞争(原来不在covert channel);
b. 攻击者训练(mistrain) BPU,使得它转跳到transmission gadgets处;
一般硬件都比模拟器的策略更激进,比如在gem5 x86 o3处理器上,我们需要13次才能训练预测部件(BPU)转跳,在intel xeon和nuc上,只需要2次。
一般来说,模拟器上的攻击比硬件上的更容易实现,因为:1. 噪音小; 2. 策略保守。但也有例外,比如store bypass (speculation window更小).
补丁
Spectre的软件补丁有很多,比如这个Prevent speculation on user controlled pointer. 但我认为在软件层面上的补丁对于spectre是不够的:首先,这是处理器设计上的问题,优雅的解决方法应该是更改设计,而不是没完没了地打补丁,就像我上面说的,潜在的旁道有很多。其次,目前的补丁问题也层出不穷,之前微软禁用了Intel的补丁,原因是补丁不稳定,会造成数据丢失、损坏和不必要的重启。
对于Spectre v1,一个思路是对代码做静态检查,以确定可能受到攻击者控制以干扰推测的代码序列。易受攻击的代码序列可以插入fence指令(例如lfence),该指令可停止推测性执行,直到执行完栅栏的所有指令为止。插入围栏说明时必须小心,因为太多说明可能会对性能产生严重影响。
对于Spectre v2,补丁有retpoline, IBPB,STIBP: conditional, RSB filling等。这里简要介绍一下retpoline:
ret指令的预测跟jmp和call不太一样,ret依赖于Return Stack Buffer(RSB)。跟indirect branch predictor不一样的是,RSB是一个 先进后出的stack。当执行call指令时,会push一项,执行ret时,会pop一项,这很容易收攻击者操纵。
1 | ;before retpoline |
- “1: call load_label”这句话把”2: pause ; lfence”的地址压栈,当然也填充了RSB的一项,然后跳到load_label;
- “4: mov %rax, (%rsp)”,这里把间接跳转的地址(*%rax)直接放到了栈顶,注意,这个时候内存中的栈顶地址和RSB里面地址不一样了;
- 如果这个时候ret CPU预测执行了,会使用第一步填充在RSB的地址进行,也就是”2: pause ; lfence”,这里是一个死循环;
- 最后,CPU发现了内存栈上的返回地址跟RSB自己预测的地址不一样,所以,预测执行会终止,然后跳到*%rax。
可想而知,retpoline的部署需要编译器的支持,最新的gcc已经支持了-mindirect-branch=thunk选项用于替换间接指令为retpoline系列。
总结
在接下来一个CPU硬件周期 (7-10年),Spectre和Meltdown将极大改变硬件和软件设计,研究人员会将旁道泄露的可能考虑进来。同时,Meltdown和Spectre的发现以及相关的补丁将在未来几年中对计算机用户产生重大影响。在短期内,补丁将对性能产生重大影响,具体取决于工作负载和特定硬件。这可能需要对某些基础架构进行操作更改。在我看来,最终解决预测攻击的方法还是一个新的ISA.
参考
Pipeline and out-of-order instruction execution optimize performance